
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Multi threaded
- 3-sigma rule
- Azimuth
- object detection
- Interference Pattern
- Data Race
- Quaternion 연산
- Reflectivity
- Motion compensate
- PYTHON
- Single threaded
- VLS-128
- Veloview
- lidar
- HDmap
- Data Packet
- coordinate system
- Phase Offset
- Frame rate
- timestamp
- Alpha Prime
- PointCloud
- Smart Pointer
- Alpha Prime(VLS-128)
- ApolloAuto
- PointCloud Frame
- 센서셋
- Phase Lock
- nvidia
- Coding Test
- Today
- Total
엔지니어 동행하기
Object Detection with CUDA-PointPillars 본문
Object Detection with CUDA-PointPillars
엔지니어 설리번 2022. 6. 5. 20:42(해당 포스팅은 NVIDIA Technical BLOG를 참고하여 작성하였습니다. )
Jetson Platform에서 사용할 수 있는 CUDA-PointPillars 모델의 Pipeline를 설명드립니다.
OpenPCDet Toolbox에서 제공하는 PointPillars 모델은 ONNX model로 export 할 수 없습니다. 또한 TensorRT에서 low performance를 갖는 small operation을 많이 갖고 있어 CUDA-PointPillars를 개발하였습니다.
CUDA-PointPillars 의 Pipeline
다음의 4단계를 통해 Point Cloud에서 Object Detect을 수행한다.

Base preprocessing
이 단계에서는 다음 3가지가 계산된다. 이 값들은 ONNX model의 input으로 사용된다.
- Base feature map // 4 channel, (x, y, z, i)
- Pillar Coordinate : 각 Pillar의 좌표
- Parameters : Pillar의 개수 // Point가 존재하지 않는 위치에는 Pillar도 존재하지 않는다.
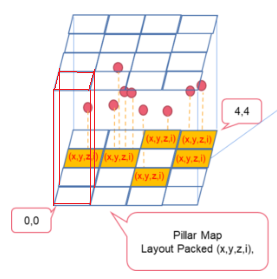
Base feature map(= Pillar map)의 4 channel은 LiDAR 좌표계를 기준으로 X-Y grid를 나누고, Pillar features를 계산한다. 이를 통해 Pillar map (x,y,z,i)를 얻고, 이 때 i 는 Pillar index를 의미한다.
//preprocess_kernels.cu
// create 4 channels
__global__ void generateBaseFeatures_kernel(unsigned int *mask, float *voxels,
int grid_y_size, int grid_x_size,
unsigned int *pillar_num,
float *voxel_features,
unsigned int *voxel_num,
unsigned int *voxel_idxs)
{
unsigned int voxel_idx = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int voxel_idy = blockIdx.y * blockDim.y + threadIdx.y;
if(voxel_idx >= grid_x_size ||voxel_idy >= grid_y_size) return;
unsigned int voxel_index = voxel_idy * grid_x_size
+ voxel_idx;
unsigned int count = mask[voxel_index];
if( !(count>0) ) return;
count = count<POINTS_PER_VOXEL?count:POINTS_PER_VOXEL;
unsigned int current_pillarId = 0;
current_pillarId = atomicAdd(pillar_num, 1);
voxel_num[current_pillarId] = count;
uint4 idx = {0, 0, voxel_idy, voxel_idx};
((uint4*)voxel_idxs)[current_pillarId] = idx;
for (int i=0; i<count; i++){
int inIndex = voxel_index*POINTS_PER_VOXEL + i;
int outIndex = current_pillarId*POINTS_PER_VOXEL + i;
((float4*)voxel_features)[outIndex] = ((float4*)voxels)[inIndex];
}
// clear buffer for next infer
atomicExch(mask + voxel_index, 0);
}(설명 추가 예정)
Preprocessing
3가지 값 중 Base feature map (4 channels)은 바로 ONNX model의 input으로 사용하지 않고, BEV feature map (10 channels)으로 변환하여 사용한다.

// 4 channels -> 10 channels
__global__ void generateFeatures_kernel(float* voxel_features,
unsigned int* voxel_num, unsigned int* voxel_idxs, unsigned int *params,
float voxel_x, float voxel_y, float voxel_z,
float range_min_x, float range_min_y, float range_min_z,
float* features)
{
int pillar_idx = blockIdx.x * WARPS_PER_BLOCK + threadIdx.x/WARP_SIZE;
int point_idx = threadIdx.x % WARP_SIZE;
int pillar_idx_inBlock = threadIdx.x/32;
unsigned int num_pillars = params[0];
if (pillar_idx >= num_pillars) return;
__shared__ float4 pillarSM[WARPS_PER_BLOCK][WARP_SIZE];
__shared__ float4 pillarSumSM[WARPS_PER_BLOCK];
__shared__ uint4 idxsSM[WARPS_PER_BLOCK];
__shared__ int pointsNumSM[WARPS_PER_BLOCK];
__shared__ float pillarOutSM[WARPS_PER_BLOCK][WARP_SIZE][FEATURES_SIZE];
if (threadIdx.x < WARPS_PER_BLOCK) {
pointsNumSM[threadIdx.x] = voxel_num[blockIdx.x * WARPS_PER_BLOCK + threadIdx.x];
idxsSM[threadIdx.x] = ((uint4*)voxel_idxs)[blockIdx.x * WARPS_PER_BLOCK + threadIdx.x];
pillarSumSM[threadIdx.x] = {0,0,0,0};
}
pillarSM[pillar_idx_inBlock][point_idx] = ((float4*)voxel_features)[pillar_idx*WARP_SIZE + point_idx];
__syncthreads();
//calculate sm in a pillar
if (point_idx < pointsNumSM[pillar_idx_inBlock]) {
atomicAdd(&(pillarSumSM[pillar_idx_inBlock].x), pillarSM[pillar_idx_inBlock][point_idx].x);
atomicAdd(&(pillarSumSM[pillar_idx_inBlock].y), pillarSM[pillar_idx_inBlock][point_idx].y);
atomicAdd(&(pillarSumSM[pillar_idx_inBlock].z), pillarSM[pillar_idx_inBlock][point_idx].z);
}
__syncthreads();
//feature-mean
float4 mean;
float validPoints = pointsNumSM[pillar_idx_inBlock];
mean.x = pillarSumSM[pillar_idx_inBlock].x / validPoints;
mean.y = pillarSumSM[pillar_idx_inBlock].y / validPoints;
mean.z = pillarSumSM[pillar_idx_inBlock].z / validPoints;
mean.x = pillarSM[pillar_idx_inBlock][point_idx].x - mean.x;
mean.y = pillarSM[pillar_idx_inBlock][point_idx].y - mean.y;
mean.z = pillarSM[pillar_idx_inBlock][point_idx].z - mean.z;
//calculate offset
float x_offset = voxel_x / 2 + idxsSM[pillar_idx_inBlock].w * voxel_x + range_min_x;
float y_offset = voxel_y / 2 + idxsSM[pillar_idx_inBlock].z * voxel_y + range_min_y;
float z_offset = voxel_z / 2 + idxsSM[pillar_idx_inBlock].y * voxel_z + range_min_z;
//feature-offset
float4 center;
center.x = pillarSM[pillar_idx_inBlock][point_idx].x - x_offset;
center.y = pillarSM[pillar_idx_inBlock][point_idx].y - y_offset;
center.z = pillarSM[pillar_idx_inBlock][point_idx].z - z_offset;
//store output
if (point_idx < pointsNumSM[pillar_idx_inBlock]) {
pillarOutSM[pillar_idx_inBlock][point_idx][0] = pillarSM[pillar_idx_inBlock][point_idx].x;
pillarOutSM[pillar_idx_inBlock][point_idx][1] = pillarSM[pillar_idx_inBlock][point_idx].y;
pillarOutSM[pillar_idx_inBlock][point_idx][2] = pillarSM[pillar_idx_inBlock][point_idx].z;
pillarOutSM[pillar_idx_inBlock][point_idx][3] = pillarSM[pillar_idx_inBlock][point_idx].w;
pillarOutSM[pillar_idx_inBlock][point_idx][4] = mean.x;
pillarOutSM[pillar_idx_inBlock][point_idx][5] = mean.y;
pillarOutSM[pillar_idx_inBlock][point_idx][6] = mean.z;
pillarOutSM[pillar_idx_inBlock][point_idx][7] = center.x;
pillarOutSM[pillar_idx_inBlock][point_idx][8] = center.y;
pillarOutSM[pillar_idx_inBlock][point_idx][9] = center.z;
} else {
pillarOutSM[pillar_idx_inBlock][point_idx][0] = 0;
... // also adapt to [1] ~ [9]
}
__syncthreads();
for(int i = 0; i < FEATURES_SIZE; i ++) {
int outputSMId = pillar_idx_inBlock*WARP_SIZE*FEATURES_SIZE + i* WARP_SIZE + point_idx;
int outputId = pillar_idx*WARP_SIZE*FEATURES_SIZE + i* WARP_SIZE + point_idx;
features[outputId] = ((float*)pillarOutSM)[outputSMId] ;
}
}(설명 추가 예정)
ONNX model for TensorRT
ONNX model로 export 가능하도록 OpenPCDet ToolBox 에서 제공하는 PointPillars 모델을 수정하였다. 수정한 이유를 정리하면 다음과 같다.
- Too many small operations, with low memory bandwidth.
- NonZero 와 같은 몇몇 연산은 TensorRT에서 지원되지 않는다.
- ScatterND와 같은 몇몇 연산은 low performance를 갖는다.
- input, output으로 사용한 "dict"은 ONNX file로 export 될 수 없다.
ONNX model의 내부 구조는 다음과 같다. ScatterBEV는 Point Pillars (1D) 을 2D image로 바꿔서 TensorRT에서 동작하도록 한다.

Post-processing
TensorRT engine의 output인 Class, Box, Dir_class으로 Bounding Box의 parameters를 계산하는 단계이다.

Detecting Objects in Point Clouds with NVIDIA CUDA-Pointpillars | NVIDIA Technical Blog
Detecting Objects in Point Clouds with NVIDIA CUDA-Pointpillars | NVIDIA Technical Blog
Use long-range and high-precision data sets to achieve 3D object detection for perception, mapping, and localization algorithms.
developer.nvidia.com
GitHub - NVIDIA-AI-IOT/CUDA-PointPillars: A project demonstrating how to use CUDA-PointPillars to deal with cloud points data fr
A project demonstrating how to use CUDA-PointPillars to deal with cloud points data from lidar. - GitHub - NVIDIA-AI-IOT/CUDA-PointPillars: A project demonstrating how to use CUDA-PointPillars to d...
github.com
'Perception Engineering (LiDAR) > Object Detection' 카테고리의 다른 글
| CUDA Programming 예제, NMS 알고리즘 처리하기(GPGPU) (0) | 2022.07.10 |
|---|---|
| Coordinate System간의 Transform(Euler, DCM, Quaternions) (0) | 2022.07.03 |
| Object Detection의 Coordinate System(WGS84, ENU, UTM, RFU) 정리 (0) | 2022.07.03 |
| Object Detection에서 Depth Cam/LiDAR/Camera 별 Coordinate System 정리 (0) | 2022.06.19 |



