
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- object detection
- Coding Test
- Azimuth
- Phase Lock
- Motion compensate
- Alpha Prime(VLS-128)
- ApolloAuto
- Single threaded
- 센서셋
- Interference Pattern
- Multi threaded
- PointCloud
- lidar
- VLS-128
- HDmap
- Quaternion 연산
- 3-sigma rule
- Smart Pointer
- coordinate system
- PointCloud Frame
- Frame rate
- Phase Offset
- Data Packet
- PYTHON
- Reflectivity
- Data Race
- nvidia
- Alpha Prime
- timestamp
- Veloview
- Today
- Total
엔지니어 동행하기
CUDA Programming 예제, NMS 알고리즘 처리하기(GPGPU) 본문
CUDA Programming 예제, NMS 알고리즘 처리하기(GPGPU)
엔지니어 설리번 2022. 7. 10. 18:00NVIDIA CUDA를 활용하여 계산을 가속화하고 결과적으로 Object Detection 컴포넌트의 출력 frame을 높일 수 있습니다. 이번 포스팅에서는 Object Detection 결과인 Bounding Box에 적용하는 NMS(Non Maximum Suppression) 알고리즘을 병렬 프로그래밍으로 작성해보겠습니다. NMS에 대한 설명보다 CUDA Programming의 전체적인 그림을 그리는데 중점을 둘 것입니다.
CUDA Programming, Data Flow
핵심 아이디어는 데이터를 CPU와 GPU사이에서 옮기는 비용이 크기 때문에, 가속하고자 하는 연산은 GPU에서 모두 끝내고, 결과 데이터만 CPU로 다시 가져오는 방식으로 프로그래밍을 한다는 것입니다.
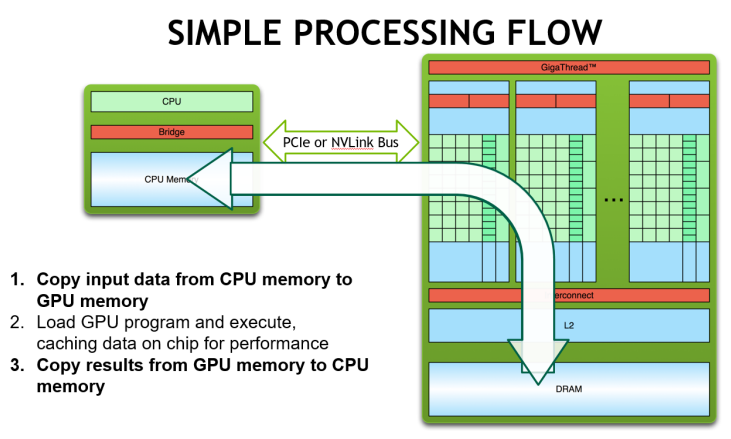
Data Flow를 3가지 단계로 설명드리겠습니다. 먼저 처리해야 할 input data를 CPU에서 GPU로 복사합니다. GPU에서 실행되는 kernel 함수(__global__)를 호출하고 input data에 대한 병렬 연산을 수행합니다. 이를 통해 가속화된 결과를 얻고 해당 데이터를 CPU로 복사합니다. 정리하면 아래와 같습니다.
CPU -> GPU (커널 호출, 병렬 처리) -> CPU
CUDA Function 정리
위에서 설명한 개념을 CUDA function과 대응해서 코드로 구현할 수 있어야 합니다. 따라서 CUDA function을 먼저 정리하겠습니다.
- malloc : CPU 메모리를 할당하고 복사할 데이터를 저장합니다.
- cudaMalloc : CPU의 데이터를 복사하기 위해, GPU 메모리를 할당합니다.
- cudaMemcpy (HostToDevice) : CPU의 데이터를 GPU 메모리에 복사합니다.
- __global__ : GPU를 이용해 가속화된 계산 결과를 얻습니다.
- cudaMemcpy (DeviceToHost) : GPU에서 계산한 결과를 CPU에 복사합니다.
- cudaFree : GPU의 메모리를 해제합니다.
Kernel Function
__global__ : GPU에서 동작하는 함수이고 CPU에서 호출합니다.

커널을 호출하는 방법은 다음과 같습니다.
function_name<<<nBlock,nThread>>>(argument list);
NMS 알고리즘 처리 예제 (GPGPU)
General Purpose 로 GPU를 사용하는 것을 GPGPU라 합니다. 이는 CUDA를 통해 가능하며 NMS 알고리즘을 구현하면 다음과 같습니다.
#include <stdio.h>
#include <cuda_runtime.h>
#include <iostream>
#include <fstream>
#include <sstream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include "opencv2/imgproc/imgproc.hpp"
#include <stdbool.h>
#include <math.h>
using namespace cv;
using namespace std;
#define BLOCKSIZE 32 //The number of threads per block should be not greater than 1024
#define gpuErrchk(ans) { gpuAssert((ans), __FILE__, __LINE__); }
inline void gpuAssert(cudaError_t code, const char *file, int line, bool abort=true)
{
if (code != cudaSuccess)
{
fprintf(stderr,"GPUassert: %s %s %d\n", cudaGetErrorString(code), file, line);
if (abort) exit(code);
}
}
typedef struct
{
float x,y,w,h,s;
}box;
__device__
float IOUcalc(box b1, box b2)
{
float ai = (float)(b1.w)*(b1.h);
float aj = (float)(b2.w)*(b2.h);
float x_inter, x2_inter, y_inter, y2_inter;
x_inter = max(b1.x,b2.x);
y_inter = max(b1.y,b2.y);
x2_inter = min((b1.x + b1.w),(b2.x + b2.w));
y2_inter = min((b1.y + b1.h),(b2.y + b2.h));
float w = (float)max((float)0, x2_inter - x_inter);
float h = (float)max((float)0, y2_inter - y_inter);
float inter = ((w*h)/(ai + aj - w*h));
return inter;
}
__global__
void NMS_GPU(box *d_b, bool *d_res)
{
int abs_y = (blockIdx.y * blockDim.y) + threadIdx.y;
int abs_x = (blockIdx.x * blockDim.x) +threadIdx.x;
float theta = 0.6;
if(d_b[abs_x].s < d_b[abs_y].s)
{
if(IOUcalc(d_b[abs_y],d_b[abs_x])>theta)
{
d_res[abs_x] = false;
}
}
}
int main()
{
int count = 6000;
bool *h_res =(bool *)malloc(sizeof(bool)*count);
for(int i=0; i<count; i++)
{
h_res[i] = true;
}
box b[count];
std::ifstream in;
std::string line;
in.open("../boxes.txt"); //y1, x1, y2, x2
if (in.is_open())
{
int i = 0;
while(getline(in, line))
{
istringstream iss(line);
iss >> b[i].y;
iss >> b[i].x;
iss >> b[i].h; //y2
iss >> b[i].w; //x2
b[i].h-=b[i].y; //y2 -> h
b[i].w-=b[i].x; //x2 -> w
i+=1;
if(i==count) break;
}
}
in.close();
in.open("../scores.txt");
if (in.is_open())
{
int i = 0;
while(in >> b[i].s)
{
i+=1;
if(i==count) break;
}
}
in.close();
box *d_b;
bool *d_res;
gpuErrchk(cudaMalloc((void**)&d_res, count*sizeof(bool)));
gpuErrchk(cudaMemcpy(d_res, h_res,sizeof(bool)*count, cudaMemcpyHostToDevice));
gpuErrchk(cudaMalloc((void**)&d_b,sizeof(box)*count));
gpuErrchk(cudaMemcpy(d_b, b,sizeof(box)*count, cudaMemcpyHostToDevice));
//Setting 1: can only work when count <= 1024
//NMS_GPU<<<dim3(1,count,1),count>>>(d_b,d_res);
//Setting 2: work when count > 1024
//NMS_GPU<<<dim3(count,count,1), 1>>>(d_b,d_res);
//Setting 3: work when count > 1024, faster than Setting 2
dim3 gridSize(int(ceil(float(count)/BLOCKSIZE)), int(ceil(float(count)/BLOCKSIZE)),1);
dim3 blockSize(BLOCKSIZE, BLOCKSIZE, 1);
NMS_GPU<<<gridSize, blockSize>>>(d_b,d_res);
cudaThreadSynchronize();
gpuErrchk(cudaMemcpy(h_res, d_res, sizeof(bool)*count, cudaMemcpyDeviceToHost));
printf("Suppressed box id:\n");
for(int i =0; i<count ; i++)
{
if(*(h_res+i) != true)
{
printf("%d ",i);
}
}
return 0;
}해당 코드에서 알고 넘어가야 하는 부분을 정리하겠습니다.
- gpuErrchk라는 매크로 함수를 이용해서 cudaMalloc, cudaMemcpy를 감싸고, 디버깅을 할 수 있도록 하였습니다.
- NMS_GPU(__global__)안에서 IOUcalc(__device__)를 호출하는 것은, GPU에서 __device__ Function을 호출한다고 정리한 부분과 일맥상통합니다.
- 커널을 호출할 때 사용한 gridSize, blockSize는 NMS_GPU함수 안에서 blockIdx, threadIdx와 대응됩니다.
https://www.olcf.ornl.gov/wp-content/uploads/2019/06/06_Managed_Memory.pdf
https://cuda.readthedocs.io/ko/latest/CUDA_int/
Introduction - CUDA programming
Terminology SIMT(Single Instruction Multiple Thread) : 하나의 명령어로 여러개의 스레드를 동작시킨다.(1개의 스레드=1개의 데이타 처리) (SIMD와 같은 개념) GPU에서 실행되는 함수를 커널(kernel)이라고 부른다.
cuda.readthedocs.io
https://github.com/jeetkanjani7/Parallel_NMS/blob/master/GPU/nms_2d.cu
GitHub - jeetkanjani7/Parallel_NMS: Parallel CUDA implementation of NON maximum Suppression
Parallel CUDA implementation of NON maximum Suppression - GitHub - jeetkanjani7/Parallel_NMS: Parallel CUDA implementation of NON maximum Suppression
github.com
'Perception Engineering (LiDAR) > Object Detection' 카테고리의 다른 글
| Coordinate System간의 Transform(Euler, DCM, Quaternions) (0) | 2022.07.03 |
|---|---|
| Object Detection의 Coordinate System(WGS84, ENU, UTM, RFU) 정리 (0) | 2022.07.03 |
| Object Detection에서 Depth Cam/LiDAR/Camera 별 Coordinate System 정리 (0) | 2022.06.19 |
| Object Detection with CUDA-PointPillars (0) | 2022.06.05 |



