
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- HDmap
- Phase Offset
- nvidia
- Veloview
- timestamp
- Data Packet
- Quaternion 연산
- Interference Pattern
- object detection
- Data Race
- coordinate system
- Smart Pointer
- Alpha Prime
- Azimuth
- lidar
- PointCloud
- Motion compensate
- Reflectivity
- PYTHON
- Coding Test
- PointCloud Frame
- 센서셋
- ApolloAuto
- Alpha Prime(VLS-128)
- Multi threaded
- 3-sigma rule
- Phase Lock
- Single threaded
- Frame rate
- VLS-128
- Today
- Total
엔지니어 동행하기
NVIDIA TensorRT(딥러닝 모델 최적화 엔진)의 장점과 가속 기법 본문
NVIDIA TensorRT(딥러닝 모델 최적화 엔진)의 장점과 가속 기법
엔지니어 설리번 2022. 6. 12. 16:37TensorRT 란 학습된 Deep Learning 모델을 최적화하여 NVIDIA GPU 상에서의 Inference 속도를 수 배 ~ 수십 배 수십 배까지 향상하는 모델 최적화 엔진을 말합니다. 왜 TensorRT를 써야 하는지 그 장점과, 가속 기법을 이해함으로써 알 수 있습니다. 관련하여 NVIDIA Technical Blog의 포스팅을 더 알기 쉽게 정리해 설명드리겠습니다.

TensorRT를 사용하지 않는 경우, Trained model을 바로 Inference에 사용하게 되는데, 학습된 모델에 대한 Optimization Step을 추가하여, Inference를 속도를 향상한다고 정리할 수 있습니다.
TensorRT의 장점 3가지
1. 대부분의 Deep Learning Frameworks (TensorFlow, PyTorch 등)에서 학습된 모델을 지원하며, NVIDIA Datacenter, Automotive, Embedded 플랫폼 등 대부분의 NVIDIA GPU 환경에서 동일한 방식으로 적용 가능
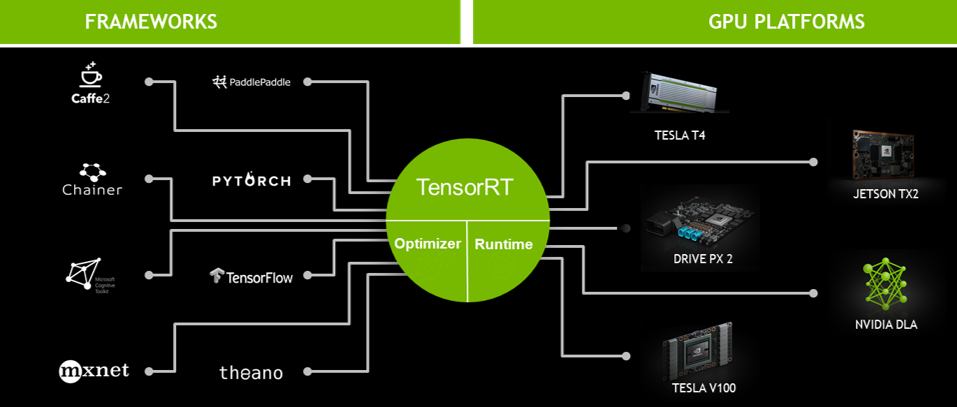
2. NVIDIA platform에서 최적의 Inference 성능을 낼 수 있도록 Network compression, Network optimization 그리고 GPU 최적화 기법들을 대상 Deep Learning 모델에 자동으로 적용
3. 다양한 Deep Learning layer 및 연산에 대하여 customization 할 수 있는 방법론을 제공하고 이를 통해 개발자들이 유연하게 TensorRT를 활용 가능 ( 참고로 NVIDIA Technical Blog에 이후 포스팅에서 자세히 설명한다 하였는데, 아직까지 포스팅이 없습니다.)
TensorRT 가속화 기법
TensorRT 최적화 엔진이 어떻게 학습된 모델을 최적화하여 가속하는지, 그 기법 4가지에 대해 설명드리겠습니다.
1. Quantization & Precision Calibration
딥러닝 프레임워크의 FP32 data type을 FP16 또는 INT8으로 바꿔서 더 적은 bit 수로 계산하는 방법입니다. 따라서 더 빠르게 계산이 가능합니다. FP16로 바꾸는 것은 Accuracy에 큰 영향을 주지 않지만 INT8로 바꾸는 경우, 문제가 있는 Netowrk가 존재하여 추가적인 Calibration이 필요합니다. TensorRT에서는 EntropyCalibrator, MinMaxCalibrator를 지원하고 있습니다.

2. Graph Optimization
TensorRT는 Vertical Layer Fusion, Horizontal Layer Fusion, Tensor Fusion을 통해 딥러닝 모델의 layer 수를 크게 감소시킵니다.

3. Kernel Auto Tuning
TensorRT는 NVIDIA의 다양한 Platform에 맞게 Runtime이 가능합니다. 즉, 각 Platform은 CUDA engine의 개수, Arichtecture, Specialized engine 포함 여부에 따라 Kernel이 다르고 TensorRT는 이에 맞는 Auto Tuning을 제공합니다. 그래서 Runtime engine build 시에 최적의 Engine Binary 생성이 가능합니다.
4. Dynamic Tensor Memory & Multi-stream execution
추가적으로 Memory management를 통해 메모리 사용량 (memory footprint)를 줄여주는 Dynamic tensor memory 기법을 사용합니다. 또한 사용자가 CUDA 언어에 대한 이해가 없더라도, 내부적으로 CUDA stream 기술을 이용하여 병렬 효율을 극대화하는 Multi-stream execution기능을 제공합니다. 이때 CUDA stream은 데이터 복사가 일어나는 중에, 데이터에 대한 처리를 동시에 하여 자원을 효율적으로 사용하는 기술을 이야기합니다.
NVIDIA TensorRT – Inference 최적화 및 가속화를 위한 NVIDIA의 Toolkit - NVIDIA Technical Blog
NVIDIA TensorRT – Inference 최적화 및 가속화를 위한 NVIDIA의 Toolkit
TensorRT는 학습된 Deep Learning 모델을 최적화하여 NVIDIA GPU 상에서의 Inference 속도를 수배 ~ 수십배 까지 향상시켜 Deep Learning 서비스 TCO (Total Cost of Ownership) 를 개선하는데 도움을 줄 수 있는 모델 최
developer.nvidia.com